实现词法分析器
对于一个token,比如用来表示数字的token:num,我们可以用正则表达式描述它,然后画出nfa,再将nfa转化成dfa,再最小化dfa的状态,但是我们的词法分析器是不是分析一个token,所以我们要把所有类型的token的dfa合并成一个dfa,这样,这个dfa也就可以识别语言的所有token了,如果在某一连串的输入下,dfa达不到终结状态,那就说明源代码有错误了。
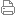
我用c#实现了一个用于《compiler construction: principles and practice》中tiny语言的词法分析器,tiny语言有关键字:if, then, else, end, repeat, until, read, write,有操作符+,-,*,/,=,<,(,),;,:=(全角逗号不算,是文章的分隔符)这10个,然后其余的token有number (一或多个数字)和identifier(一或多个字母),其dfa如下图:
上面这张图和《编译原理及实践》中的一样,其中的带中括号的输入说明这个输入是lookahead的,在匹配成功后是要重新放回输入流中的,比如识别num时,如果发现个非digit的,那就说明识别到了一个number,但是最后识别的那个非digit字符是要放回输入流的,因为它要留着下一次识别。
其中从start到done的那个other,指所有非white space,非{,非letter,非digit,也非:的字符,它有可能是合法的+, *, /这些,也可能是不合法的其它输入,如#号。因此,done这个状态只是说本次gettoken已经结束,状态机是有可能因为不合法的输入而进入done状态的。究竟从start到done是因为合法的,如+号导致的,还是由不合法的如#号导致的,将在代码中实现判断,但可以肯定的是,不管是+号还是#号作用于start状态,都会进入done状态。 |





 发表于 2014-2-17 23:14:59
发表于 2014-2-17 23:14:59

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 收藏
收藏 分享
分享 顶
顶 踩
踩 楼主
楼主